Predicting Stock Prices with Deep Neural Networks
💡 Tip: If you are just getting started on AI and machine learning, you may want to check out our Introduction to AI for Finance video tutorial first before diving into this project!
💡 Tip: Want to analyze stock market data without a single line of code? Please check out Wisesheets.io, AI-powered spreadsheets for market analysis.
Deep learning is part of a broader family of machine learning methods based on artificial neural networks, which are inspired by our brain's own network of neurons. Among the popular deep learning frameworks, Long short-term memory (LSTM) is a specialized architecture that can "memorize" patterns from historical sequences of data and extrapolate such patterns to future events.
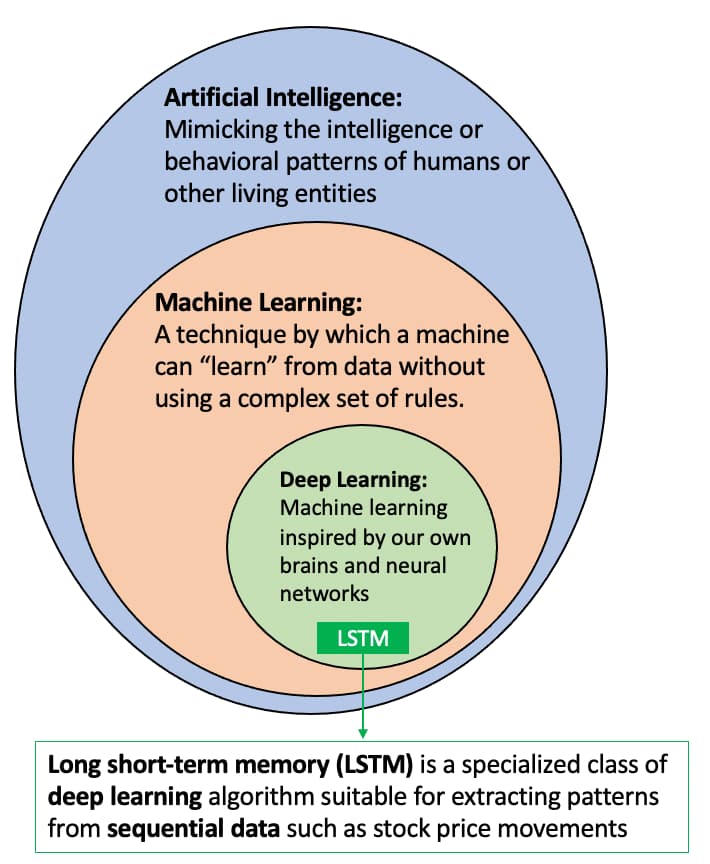
(Illustration adapted from Wikipedia)
Since the financial market is naturally comprised of historical sequences of equity prices, more and more quantitative researchers and finance professionals are using LTSM to model and predict market price movements. In this project, we will go through the end-to-end machine learning lifecycle of developing an LTSM model to predict stock market prices using Python (PyTorch) and Alpha Vantage APIs.
The project is grouped into the following sections, which are representative of a typical machine learning workflow:
❚ Installing Python dependencies
❚ Data preparation: acquiring data from Alpha Vantage stock APIs
❚ Data preparation: normalizing raw data
❚ Data preparation: generating training and validation datasets
❚ Defining the LSTM model
❚ Model training
❚ Model evaluation
❚ Predicting future stock prices
By the end of this project, you will have a fully functional LSTM model that predicts future stock prices based on historical price movements, all in a single Python file. This tutorial has been written in a way such that all the essential code snippets have been embedded inline. You should be able to develop, train, and test your machine learning model without referring to other external pages or documents.
Let's get started!
Installing Python dependencies
We recommend using Python 3.6 or higher for this project. If you do not have Python installed in your local environment, please visit python.org for the latest download instruction.
With Python installed, please go to the Command Line interface of your operating system and use the "pip install" prompts below to install Numpy, PyTorch, Matplotlib, and Alpha Vantage, respectively:
❚ numpy: pip install numpy
❚ PyTorch: pip install torch
❚ matplotlib: pip install matplotlib
❚ alpha_vantage: pip install alpha_vantage
Now, create a new Python file named project.py and paste the following code into the file:
If your have succesfully installed all the Python dependencies above, you should see the text "All libraries loaded" after running the project.py file.
Now append the following code to the project.py file. Don't forget to replace "YOUR_API_KEY" with your actual Alpha Vantage API key, which can be obtained from the Alpha Vantage support page.
Over the course of this project, we will continue adding new code blocks to the project.py file. By the time you reach the end of the tutorial, you should have a fully functional LSTM machine learning model to predict stock market price movements, all in a single Python script. Please feel free to compare your project.py with the source code if you would like to have a "sanity check" anytime during the project.
Data preparation: acquiring data from Alpha Vantage stock APIs
In this project, we will train an LSTM model to predict stock price movements. Before we can build the "crystal ball" to predict the future, we need historical stock price data to train our deep learning model. To this end, we will query the Alpha Vantage stock API via a popular Python wrapper (optionally, please refer to this market data API review across multiple asset classes such as equities, forex, and technical indicators). For this project, we will obtain over 20 years of daily close prices for IBM from November 1999 to April 29, 2021.

Append the following code block to your project.py file. If you re-run the file now, it should generate a graph similar to above thanks to the powerful matplotlib library.
Please note that we are using the adjusted close field of Alpha Vantage's daily adjusted API to remove any artificial price turbulences due to stock splits and dividend payout events. It is generally considered an industry best practice to use split/dividend-adjusted prices instead of raw prices to model stock price movements.
Data preparation: normalizing raw financial data
Machine learning algorithms (such as our LSTM algorithm) that use gradient descent as the optimization technique require data to be scaled. This is due to the fact that the feature values in the model will affect the step size of the gradient descent, potentially skewing the LSTM model in unexpected ways.
This is where data normalization comes in. Normalization can increase the accuracy of your model and help the gradient descent algorithm converge more quickly. By bringing the input data on the same scale and reducing its variance, none of the weights in the artificial neural network will be wasted on normalizing tasks, which means the LSTM model can more efficiently learn from the data and store patterns in the network. Furthermore, LSTMs are intrinsically sensitive to the scale of the input data. For the above reasons, it is crucial to normalize the data.
Since stock prices can range from tens to hundreds and thousands - $40 to $160 per share in the case of IBM - we will perform normalization on the stock prices to standardize the range of these values before feeding the data to the LSTM model. The following code snippet rescales the data to have a mean of 0 and the standard deviation is 1.
Append the following data normalization code block to your project.py file.
Data preparation: generating training and validation datasets
Supervised machine learning methods such as LSTM learns the mapping function from input variables (X) to the output variable (Y). Learning from the training dataset can be thought of as a teacher supervising the learning process, where the teacher knows all the right answers.
In this project, we will train the model to predict the 21st day's close price based on the past 20 days' close prices. The number of days, 20, was selected based on a few reasons:
❚ When LSTM models are used in natural language processing, the number of words in a sentence typically ranges from 15 to 20 words
❚ Gradient descent considerations: attempting to back-propagate across very long input sequences may result in vanishing gradients (more on this later)
❚ Longer sequences tend to have much longer training times
After transforming the dataset into input features and output labels, the shape of our X is (5388, 20), with 5388 being the number of rows and each row containing a sequence of past 20 days' prices. The corresponding Y data shape is (5388,), which matches the number of rows in X.
We also split the dataset into two parts, for training and validation. We split the data into 80:20 - 80% of the data is used for training, with the remaining 20% for validating our model's performance in predicting future prices. (Alternatively, another common practice is to split the initial data into train, validation, and test set in a 70/20/10 allocation, where the test dataset is not used at all during the training process.) The following graph shows the portion of data for training and validation - roughly speaking, data before ~2017 are used for training and data after ~2017 are used for model performance validation.

Append the following code block to your project.py file. If you re-run the file now, it should generate a graph similar to above, where the training data is colored in green and validation data is colored in blue.
We will train our models using the PyTorch framework, a machine learning library written in Python. At the heart of PyTorch's data loading utility is the DataLoader class, an efficient data generation scheme that leverages the full potential of your computer's Graphics Processing Unit (GPU) during the training process where applicable. DataLoader requires the Dataset object to define the loaded data. Dataset is a map-style dataset that implements the __getitem__() and __len__() protocols, and represents a map from indices to data samples.
Append the following code block to your project.py file to implement the data loader functionality.
Defining the LSTM model
With the training and evaluation data now fully normalized and prepared, we are ready to build our LSTM model!
As mentioned before, LSTM is a specialized artificial neural network architecture that can "memorize" patterns from historical sequences of data and extrapolate such patterns for future events. Specifically, it belongs to a group of artificial neural networks called Recurring Neural Networks (RNNs).
LSTM is a popular artificial neural network because it manages to overcome many technical limitations of RNNs. For example, RNNs fail to learn when the data sequence is greater than 5 to 10 due to the vanishing gradients problem, where the gradients are vanishingly small, effectively preventing the model from learning. LSTMs can learn long sequences of data by enforcing constant error flow through self-connected hidden layers, which contain memory cells and corresponding gate units. If you are interested in learning more about the inner workings of LSTM and RNNs, this is an excellent explainer for your reference.
Our artificial neural network will have three main layers, with each layer designed with a specific logical purpose:
❚ linear layer 1 (linear_1): to map input values into a high dimensional feature space, transforming the features for the LSTM layer
❚ LSTM (lstm): to learn the data in sequence
❚ linear layer 2 (linear_2): to produce the predicted value based on LSTM's output
We also add Dropout, where randomly selected artificial neurons are ignored during training, therefore regularizing the network to prevent overfitting and improving overall model performance. As an optional step, we also initialize the LSTM's model weights, as some researchers have observed that it could help the model learn more efficiently.
Append the following code block to your project.py file to specify the LSTM model.
Model training
The LSTM model learns by iteratively making predictions given the training data X. We use mean squared error as the cost function, which measures the difference between the predicted values and the actual values. When the model is making bad predictions, the error value returned by the cost function will be relatively high. The model will fine-tune its weights through backpropagation, improving its ability to make better predictions. Learning stops when the algorithm achieves an acceptable level of performance, where the error value returned by the cost function on the validation dataset is no longer showing incremental improvements.
We use the Adam optimizer that updates the model's parameters based on the learning rate through its step() method. This is how the model learns and fine-tunes its predictions. The learning rate controls how quickly the model converges. A learning rate that is too high can cause the model to converge too quickly to a suboptimal solution, whereas smaller learning rates require more training iterations and may result in prolonged duration for the model to find the optimal solution. We also use the StepLR scheduler to reduce the learning rate during the training process. You may also try the ReduceLROnPlateau scheduler, which reduces the learning rate when a cost function has stopped improving for a "patience" number of epochs. Choosing the proper learning rate for your project is both art and science, and is a heavily researched topic in the machine learning community.
Append the following code block to your project.py file and re-run the file to start the model training process.
After running the script, you will see something similar to the following output in your console:
Epoch[1/100] | loss train:0.063952, test:0.001398 | lr:0.010000
Epoch[2/100] | loss train:0.011749, test:0.002024 | lr:0.010000
Epoch[3/100] | loss train:0.009831, test:0.001156 | lr:0.010000
Epoch[4/100] | loss train:0.008264, test:0.001022 | lr:0.010000
...
Epoch[97/100] | loss train:0.006143, test:0.000972 | lr:0.000100
Epoch[98/100] | loss train:0.006267, test:0.000974 | lr:0.000100
Epoch[99/100] | loss train:0.006168, test:0.000985 | lr:0.000100
Epoch[100/100] | loss train:0.006102, test:0.000972 | lr:0.000100
Using mean squared error as the loss function to optimize our model, the above log output are step-by-step "loss" values calculated based on how well the model is learning. After every epoch, a smaller loss value indicates that the model is learning well, and 0.0 means that no mistakes were made. Loss train gives an idea of how well the model is learning, while loss test shows how well the model generalizes to the validation dataset. A well-trained model is identified by a training and validation loss that decreases to the point of negligible differences between the two final loss values (at this stage, we say the model has "converged"). Generally, the loss values of the model will be lower on the training than on the validation dataset.
Model evaluation
To visually inspect our model's performance, we will use the newly trained model to make predictions on the training and validation datasets we've created earlier in this project. If we see that the model can predict values that closely mirror the training dataset, it shows that the model managed to memorize the data. And if the model can predict values that resemble the validation dataset, it has managed to learn the patterns in our sequential data and generalize the patterns to unseen data points.

Append the following code block to your project.py file. Re-running the file should generate a graph similar to the figure above.
From our results, we can see that the model has managed to learn and predict on both training (green) and validation (blue) datasets very well, as the "Predicted prices" lines significantly overlap with the "Actual prices" values.
Let's zoom into the chart and look closely at the blue "Predicted price (validation)" segment by comparing it against the actual prices values.

Append the following code block to your project.py file and re-run the script to generate the zoomed-in graph.
What a beautiful graph! You can see that the predicted prices (blue) significantly overlap with the actual prices (black) of IBM.
It is also worth noting that model training & evaluation is an iterative process. Please feel free to go back to the model training step to fine-tune the model and re-evaluate the model to see if there is a further performance boost.
Predicting future stock prices
By now, we have trained an LSTM model that can (fairly accurately) predict the next day's price based on the past 20 days' close prices. This means we now have a crystal ball in hand! Let's supply the past 20 days' close prices to the model and see what it predicts for the next trading day (i.e., the future!). Append the following code to your project.py file and re-run the script one last time.
Running the script will generate a prediction graph similar to the one below:

The red dot in the graph is what our model predicts for IBM's close price on the next trading day.
Is the prediction good enough? How about other stocks such as TSLA, APPL, or the Reddit-favorite Gamestop (GME)? What about other asset classes such as forex or cryptocurrencies? Beyond the close prices, are there any other external data we can feed to the LSTM model to make it even more robust - for example, one of the 50+ technical indicators from the Alpha Vantage APIs?
Now that you have learned the fundamentals of machine learning for financial market data, the possibility is limitless. We hereby pass the baton to you, our fearless reader!
References
Full project.py source code: link
To submit your questions or comments via GitHub Issues: link
To run the script on a Google Colab Jupyter notebook with access to GPU: link
To run the script on your local Jupyter Notebook:
git clone https://github.com/jinglescode/time-series-forecasting-pytorch.git
pip install -r requirements.txt
View other Alpha Academy projects →
If you are interested in translating this project into a language other than English, please let us know and we truly appreciate your help!
Wenn Sie daran interessiert sind, dieses Projekt ins Deutsche zu übersetzen, lassen Sie es uns bitte wissen und wir bedanken uns sehr für Ihre Hilfe!
Si está interesado en traducir este proyecto al español, háganoslo saber y realmente apreciamos tu ayuda.
Se você está interessado em traduzir este projeto para o português, por favor nos avise e nós realmente apreciamos sua ajuda!
如果您有兴趣把这篇文章翻译成中文, 请联系我们。我们非常感谢您的支持!
本プロジェクト和訳にご興味お持ちの方々、是非、お問い合わせください!ご連絡お待ちしております!
이 프로젝트를 한국어로 번역하는 데 관심이 있으시면 저희에게 알려주십시오. 도움을 주셔서 정말 감사합니다!
Disclaimer: All content from the Alpha Academy is for educational purposes only and is not investment advice.